By Orlando Trejo
Written For humans. Curated by Bots.
Do we write for humans or bot crawlers? That's the question haunting every online content creator today.
The truth is that you have to write for the bots first.
What that means is that for human readers to find your online content, it has to first be curated by a bot.
That's why content creators like you need to keep their H1 (and other tags) very descriptive, and also concise so that Google's spiders can find your content, index it, and offer it up to human readers searching for it.
So, once we understand this concept, can we harness the power of spider crawlers to create content?
Relax, we're not suggesting that spider bots will pen your next blog (AI is already doing that), but what every content creator knows is that the best performing blogs are usually the best-researched blogs.
Why is that?
Readers appreciate finding the correct answers to their queries, particularly when searching for topics related to product comparisons or reviews, where having a lot of information will help them make the right decisions.
That means that a well-researched blog is an excellent blog, and an excellent blog is a blog that is valued by your readers, more likely to be shared, generates more views, and, ultimately, conversions.
But what happens when your subject matter is vast? Like, for example, finding a list of all the best IT Conferences of 2020. Or a list of all colleges in the USA offering scholarships for a particular group of IT students?
Enter The Web Crawlers
So if spider bots and web crawlers are so good at finding content and indexing it for web giants like Google, can we, mere coders, harness some of that web crawling power to research and index content for our blogs?
Can a simple web crawling program save you hours of research time and help you provide the best and most accurate content to your readers?
The answer is a resolute yes.
How To Use Web Crawler Bots for Content Research
The Challenge: Find a list of the best IT Conferences happening in 2020 (with location, dates, cost, URL).
We first identify several companies that run the type of conferences we are looking for and find their events page.
Like, for example, The FutureCon Events Page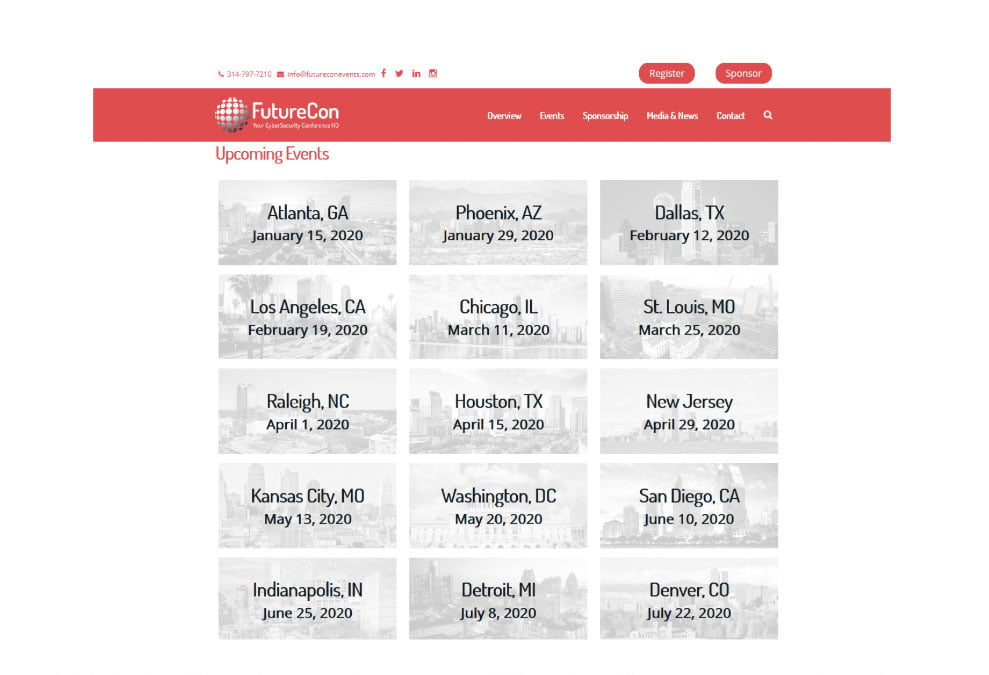
Step 1
We want to scrape the FutureCon Events page of data related to event locations, dates and URLs. To do this, we'll use a web crawler to output a list with these elements in CSV format that can then be used in Excel or Google Sheets.
Step 2
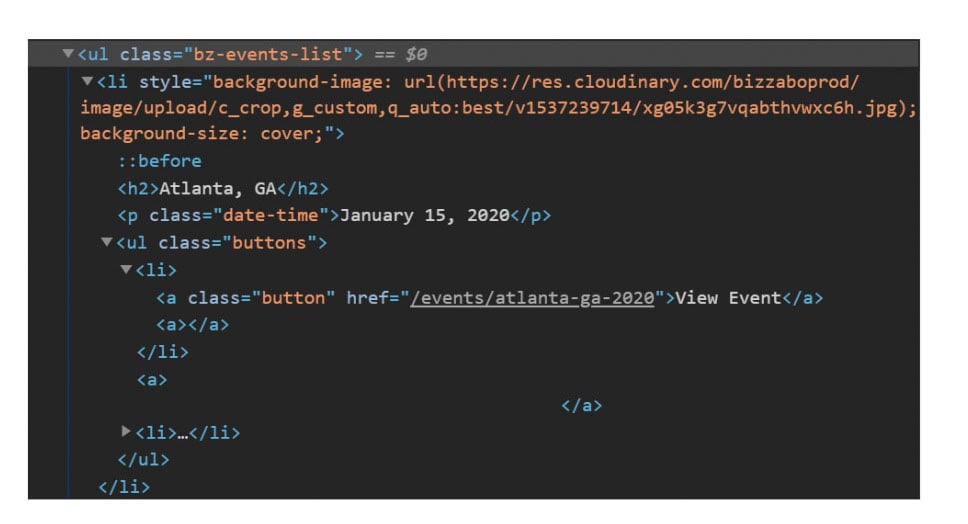
Using the Browser Inspect Element Tool, we can access the HTML source code for each event.
In the screenshot above, we can see there is a CSS class named "bz-events-list" that defines the style for each event.
In each event (starting with the HTML tag li), we can see that the city (location) is inside an <h2> tag, the date is inside a <p> tag with CSS class “date-time”, and the URL is inside an <a> tag with CSS class “button”
That is the information we want to extract from every event automatically.
Step 3

There are many tools for building web scrapers. In this example, we will use Scrapy, which is a very versatile Python framework used to extract data using a set of scripts known as "Spiders."
Step 4
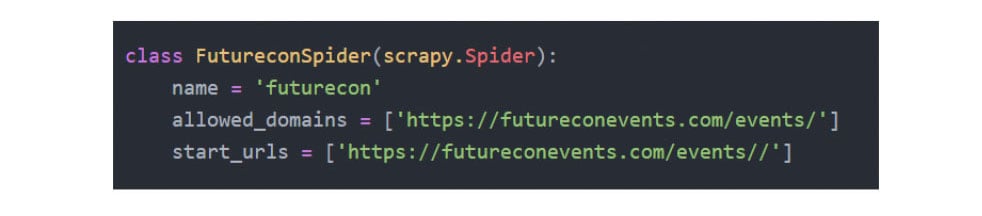
Scrapy comes with a set of predefined crawling scripts, which consist mainly of a Python program using a class named "Spider". In this example, we run the start script for the Futurecon project, and Scrapy generates all the required files.
We edit the "start URL" and the "parse" function (shown below), which contains the HTML tags and CSS classes of interest for the scraping project.
Step 5
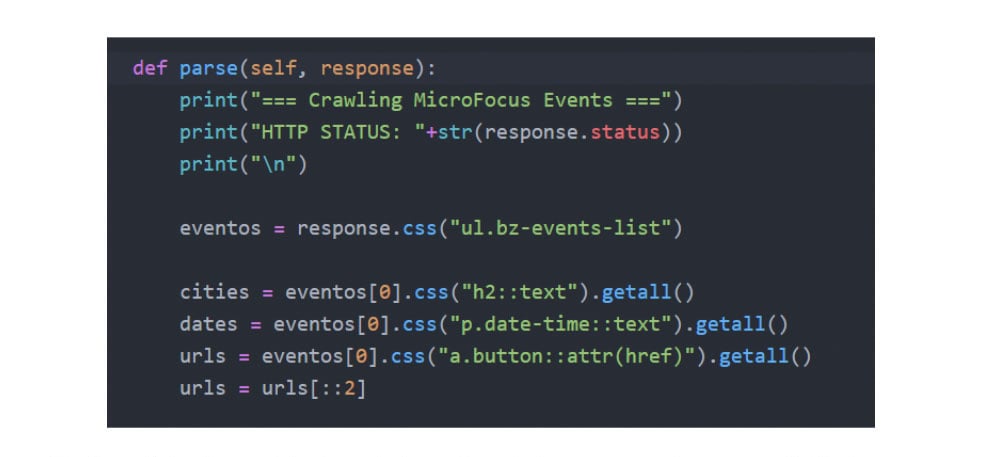
The "parse" function contains the main instructions for the scraper, and we can see in this image what we are looking for:
• "eventos" is a list with scraped elements starting from the <ul> HTML tag and the "bz-events-list" CSS class, which we defined previously as the container for our event list.
• "cities" is a list containing the text from <h2> HTML tags from every "eventos" instance.
• "dates" is a list containing the text from <p> HTML tags and "date-time" CSS class from every "eventos" instance.
• "urls" is a list containing the links from <a> HTML tags and "button" CSS class, and extracting the "href" attributes, from every "eventos" instance.
Step 6
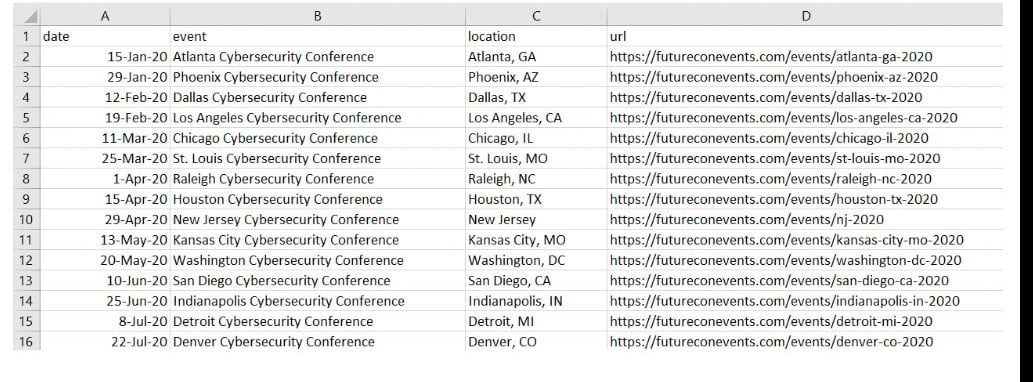
After a few string tweaks using Python, and funneling the output to the "yield" Python function, we obtain a list in CSV format, ready to be used by our end application.
Conclusion
So there you have it. A few lines of code can save your content team many hours of research and help you deliver the type of content that your customers appreciate and reward with shares and conversions. We used this technique when researching the SherpaDesk Blog Top IT Conferences of 2020 (That You Should Attend) Part 1.
If you have any questions feel free to hit us up at our sub-reddit (r/sherpadesk), and you can always contact us at: Support@SherpaDesk.com
%201.png?width=559&height=559&name=close-up-women-working-with-devices%20(1)%201.png)